
RabbitMQ Python 教程翻译:工作队列,Work Queues
(使用Pika Python客户端)
前提
本教程假设 RabbitMQ 已经 安装 ,并且在 localhost 的标准端口 (5672) 上运行。如果你用的是别的主机名、端口号或认证信息,那么,连接设置会需要进行调整。
如何寻求帮助
如果你在学习本教程时遇到困难,那么,可通过邮件列表来 与我们联系 。
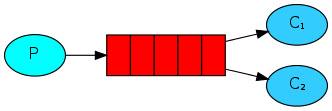
本教程的关注点
在 第一个教程 中,我们写了两个程序,它们会围绕一个指定名字的队列进行操作,分别向其中发送消息及从中接收消息。在本教程中,我们会创建一个 工作队列 ,它会被用来将一些很耗时的任务分发给多个工作者。
使用工作队列(或者说任务队列)的主要出发点是,不要立即开始进行一项非常消耗资源的任务并且干等着它完成,而是将它列入计划中并在日后执行该任务。我们会将每个 任务 封装成一个消息,并将该消息发送到某个队列中去。后台运行的某个工作者进程,会从队列中取出任务,并最终执行对应的工作。如果你运行多个工作者进程,那么它们会一起分担那些任务。
这种概念,在网页应用中尤其有用,因为,你是无法在一个短暂的HTTP 请求窗口期内完成复杂的任务的。
在这套教程里之前的部分中,我们发送了一条消息,其它包含着"Hello World!"内容。现在,我们将会发送一些用于表示复杂任务的字符串。此处,我们并不真正去执行那些现实场景下的任务,像是对图片进行缩放或是对 pdf 文件进行渲染之类的任务,所以,我们只是假装在执行任务,就好像真的是很繁忙一样——具体做法就是,使用time.sleep()函数来造成一个延迟。我们会将字符串中包含的小数点的个数当成它的复杂度;每个小数点,相当于一秒钟的“工作”。例如,以Hello...表示的假任务,会花费三秒钟的时间。
我们将会稍微修改一下上个示例中的send.py代码,以使得可以通过命令行参数来任意指定要发送的消息内容。这个程序会将任务分发到我们的工作队列中去,因此,将它改名为new_task.py:
import sys
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key= 'hello' ,
body=message)
print(" [x] Sent %r" % message)
之前的receive.py脚本也需要修改:对于消息体中的每个小数点,它都要假装做了一秒钟的工作。它会从队列中取出消息,并执行对应的任务,因此改名为worker.py:
import time
def callback(ch, method, properties, body):
print( " [x] Received %r" % body)
time.sleep(body.count( b'.' ))
print( " [x] Done" )
轮询分发
使用任务队列的其中一个好处就是,可以轻易地实现并行工作。如果我们积压了很多工作,那么,我们只需要增加更多的工作者,这样就能轻易地扩容。
首选,我们尝试同时运行两个worker.py脚本实例。它们都会从队列中获取到消息,但是具体情形是怎么样的呢?让我们仔细观察。
你需要打开三个终端。其中两个会运行worker.py脚本。这两个终端,就是我们的两个消费者——C1和C2。
# 终端1
python worker.py
# => [*] Waiting for messages. To exit press CTRL+C
# 终端2
python worker.py
# => [*] Waiting for messages. To exit press CTRL+C
我们在第三个终端中发布新任务。一旦你启动了消费者进程,你就可以开始发布新消息了:
# 终端3
python new_task.py First message.
python new_task.py Second message..
python new_task.py Third message...
python new_task.py Fourth message....
python new_task.py Fifth message.....
看看工作者进程都收到了什么:
# 终端1
python worker.py
# => [*] Waiting for messages. To exit press CTRL+C
# => [x] Received 'First message.'
# => [x] Received 'Third message...'
# => [x] Received 'Fifth message.....'
# 终端2
python worker.py
# => [*] Waiting for messages. To exit press CTRL+C
# => [x] Received 'Second message..'
# => [x] Received 'Fourth message....'
默认情况下,RabbitMQ会按照顺序将新消息发送给下一个消费者。平均来看,每个消费者都会收到相同数量的消息。这种消息分发方式被称为轮询。启动三个或四个工作者进程,再感受一下。
消息确认
执行任务可能会花费数秒钟的时间。你可能会好奇,假如某个消费者启动了一个耗时很长的任务并在没完成的时候就崩溃了,会怎么样。对于此刻的代码,一旦RabbitMQ将消息分发到某个消费者,它立即就会标记该消息为待删除状态。在这种情况下,如果你杀死一个工作者进程,那么,它刚才正在处理的消息就会丢失了。其它所有已经被分发给这个工作者但尚未被处理的消息,也会丢失。
然而,我们并不希望丢失任何任务信息。如果某个工作者进程崩溃了,我们希望那个任务被分发给别的工作者。
为了避免消息的丢失,RabbitMQ支持 消息确认 。确认消息,是由消费者回发的,用于向RabbitMQ告知,某个消息已经收到、已经处理完毕、RabbitMQ可以将它删除了。
如果某个消费者崩溃了(通道被关闭、连接被关闭、或者TCP 连接断开)而且还没有发送确认消息,那么,RabbitMQ就知道,某条消息还没有被完全处理完毕,于是就会将它重新加入队列。如果此时还有其它消费者在线的话,那么,这条消息被会立即被重新分发给另一个消费者。这样,你就可以确信,不会有消息发生丢失,即使某些工作者进程偶尔崩溃也没关系。
消息没有超时时间;一旦有消费者进程崩溃了,RabbitMQ就会重新分发消息。即使需要花很长很长的时间来处理某条消息,也没关系。
手动确认消息选项 默认 是处于启用状态。 在前一个示例中,我们有意地通过 auto_ack=True 标志来关闭了这个选项。现在 ,应当去掉这个标志了,等到工作者进程完成了一项任务之后,再明确地发送一条对应的确认消息。
def callback(ch, method, properties, body):
print( " [x] Received %r" % body)
time.sleep( body.count( '.' ) )
print( " [x] Done" )
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(queue='hello', on_message_callback=callback)
利用这段代码,就可以确保,即使你在某个工作者进程处理某条消息时按下CTRL+C 杀死了它,也不会丢失任何信息。那个工作者进程崩溃后,所有尚未被确认的消息都会被重新分发。
确认消息,必须 在之前收到实际任务消息的相同通道上回发。如果试图在不同的通道上回发确认消息的话,会引起通道级别的协议异常。参考 确认消息说明文档 以了解更多细节。
忘记回发确认消息
经常会有人忘记了调用basic_ack 。这种错误很容易发生,但却会带来严重的后果。当你的客户端退出时,消息会被重新分发(看起来就像是随机重新分发一样),而RabbitMQ会消耗越来越多的内存,因为,所有未被确认的消息,都不能释放掉。
可使用 rabbitmqctl 输出 messages_unacknowledged 属性的值,以调查这种错误:
sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
在Windows系统中,去掉开头的sudo:
rabbitmqctl.bat list_queues name messages_ready messages_unacknowledged
消息的持久存储
我们已经学到了,如何确保,即使在消费者进程崩溃的情况下,也不丢失任务信息。然而,当RabbitMQ 服务器退出时,我们的任务还是会丢失。
当RabbitMQ退出或者崩溃时,会忘记所有的队列以及其中的消息,除非你告诉它不要忘记。为了确保消息不丢失,需要做两件事:必须将队列和消息都标记为持久存储的。
首选,要确保,当某个RabbitMQ 节点重启时,队列继续存在。要实现这一点,我们就需要将它声明为持久存储的(durable):
channel.queue_declare(queue='hello', durable=True)
尽管这条命令本身是正确的,但是,在我们目前的状况下,它还不能正常工作。那是因为,我们已经定义了一个名为hello的队列,并且是不持久存储的。RabbitMQ不允许你以不同的参数来重新定义一个已有的队列,任何程序试图这样做的话,都会收到一个错误。不过呢,我们可以快速绕过这个问题——定义一个名字不同的队列,例如名字叫做task_queue:
channel.queue_declare(queue='task_queue', durable=True)
在生产者和消费者代码里都要做出与queue_declare相关的修改。
到目前为止,我们可以确保,即使RabbitMQ 重启了,task_queue队列也不会丢失。现在,我们需要将消息也标记为持久的——将delivery_mode属性的值设置为2。
channel.basic_publish(exchange='',
routing_key= "task_queue" ,
body=message,
properties=pika.BasicProperties(
delivery_mode = 2 , # 让消息变成持久存储的
))
与消息持久存储相关的注意事项
将消息标记为持久存储的,并不能完全确保消息不丢失。尽管这会导致RabbitMQ将消息保存到硬盘上去,但是,仍然会有一个短暂的时间窗口,在这段时间里,RabbitMQ 收到了消息却还没有将它保存到硬盘。另外,RabbitMQ也并不会针对每条消息都调用 fsync(2) ——可能消息刚刚被保存到缓存中而还会真正被写入到硬盘上。所以,此处的持久存储保证,并不是一个强烈的保证,但是对于我们这个简单的任务队列来说,已经足够了。如果你需要更强烈的保证,那么,可以使用 发布者消息确认 。
公平分发
你可能注意到了,此刻的消息分发状况,仍然跟我们预期的不太相同。例如,在某个有两个工作者进程的场景下,所有奇数编号的消息都是很重的任务,而偶数编号的消息都是很轻的任务,那么,其中一个工作者会经常处于繁忙状态,而另一个工作者却几乎不做什么工作。当然,RabbitMQ并不知道这种实情,因而仍然会均匀地分发消息。
发生这种情况,是因为,RabbitMQ会在消息进入队列的时刻就开始分发那条消息。它并不会查看某个消费者还有多少未确认的消息。它只是盲目地将第n条消息分发给第n个消费者。

为了解决这个问题,我们可以使用通道的Channel#basic_qos方法,并设置prefetch_count=1选项。这个调用,会通过basic.qos这个协议方法来告诉RabbitMQ,不要同时向某个工作者发送超过一条的消息。或者,换句话说,在某个工作者处理完某条消息并且确认之前,不要向它发送新的消息。它会将新消息分发给下一个目前并不繁忙的工作者。
channel.basic_qos(prefetch_count=1)
与队列长度相关的注意事项
如果所有的工作者都处于繁忙状态,那么,你的队列就会填满。你需要留意这一点,可能需要对应地添加更多工作者,或者,使用 消息生存时间 功能。
将全部概念放到一起
new_task.py ( 源代码文件 )
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(
pika.ConnectionParameters(host= 'localhost' ))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(
exchange= '' ,
routing_key= 'task_queue' ,
body=message,
properties=pika.BasicProperties(
delivery_mode= 2 , # make message persistent
))
print(" [x] Sent %r" % message)
connection.close()
worker.py ( 源代码文件 )
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(
pika.ConnectionParameters(host= 'localhost' ))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C')
def callback(ch, method, properties, body):
print( " [x] Received %r" % body)
time.sleep(body.count( b'.' ))
print( " [x] Done" )
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(queue='task_queue', on_message_callback=callback)
channel.start_consuming()
利用确认消息和预取数量(prefetch_count)功能,就可以建立一个工作队列。利用持续存储选项,可以实现,即使RabbitMQ 重启了,那些任务仍然存在。
现在,可以去研究 教程3 ,如何将同一条消息分发给多个消费者。
确诊人数报表
Your opinions Email:Website url:Opinion content:
Email:Website url:Opinion content:HxLauncher: Launch Android applications by voice commands
 kill -9 18998
kill -9 18998